Polish Beats English: What New Research Means for Your AI Usage
March 23, 2026
Stanislav Lvovsky
Stanislav Lvovsky
A groundbreaking benchmark exposes surprising LLM performance gaps — and gives you practical strategies to work around them
If you’ve been using ChatGPT, Claude, or Gemini, you probably assumed they work best in English. After all, most AI training data is in English, right? A groundbreaking new study just shattered this assumption. Polish consistently outperforms English. Chinese lags far behind despite having over a billion speakers. And the language you choose can make a 30% difference in how well AI understands your long documents.
Welcome to the surprising reality of multilingual AI, where bigger isn’t always better — and your language choice matters more than you think
In this article, we’ll briefly explore what the OneRuler research discovered about how AI handles different languages, then dive into practical strategies you can use today to get better results from ChatGPT, Claude, Gemini, and other AI tools when working with long documents.
What OneRuler Discovered
Researchers from UMass Amherst just published OneRuler, the first comprehensive test of how well AI models handle long conversations and documents across 26 different languages. They tested major models like Gemini, GPT, Claude, and others by giving them increasingly long texts — from about 6 pages to 100+ pages — and asking them to find information buried within.
The results were — let’s say, unexpected. Polish ranked #1 at 88% accuracy. English? It came in 6th place at 83.9%. Chinese, despite having 1.4 billion speakers and massive amounts of training data, scored only 62.1% — ranking 22nd out of 26 languages tested.
Furthermore, as documents got longer, the gap between best worsst performing languages grew wider. At shorter lengths, all languages performed similarly. But when researchers pushed to 100+ page documents, the difference between the best and worst languages jumped from 11% to 34%.
Two Types of Tasks: Why Retrieval Works But Aggregation Fails
The researchers tested AI models on two fundamentally different types of tasks, and the results reveal a critical limitation you need to understand.
Retrieval tasks (NIAH — “Needle in a Haystack”) ask the AI to find specific information buried in a long document. For example: “What was the delivery date mentioned in this contract?” or “What did the CEO say about quarterly revenue?” Models performed reasonably well here — achieving 80–90% accuracy for high-resource languages, though performance dropped for longer documents.
Aggregation tasks (called CWE — “Common Word Extraction”) require the AI to analyze patterns across an entire document or across multiple texts. The simple version: “What are the 10 most frequently occurring words in this text?” But aggregation isn’t limited to counting words. It includes any task requiring synthesis or pattern recognition across large amounts of text:
Identifying recurring themes across multiple research papers
Comparing three novels and noting which narrative devices appear in all three
Determining which design patterns appear across multiple code repositories
Recognizing plot situations or scenarios that repeat across different chapters of a book
On aggregation tasks, even the best AI models failed spectacularly. For the “easy” version where target words appeared 30 times more often than distractors, accuracy was only 31%. For the “hard” version with closer frequencies, accuracy dropped below 1% — essentially random guessing.
This matters practically: AI can help you find specific information in long documents, but it cannot reliably count, rank, or identify patterns across them. If you’re analyzing three novels to find common narrative devices, the AI might help you search each novel individually, but asking it to synthesize patterns across all three will produce unreliable results.
Understanding Tokens: Why Language Matters
To understand why performance varies so dramatically across languages, you need to know about “tokens” — the building blocks AI models use to process text. A token is roughly a word or a piece of a word — think of it as the smallest unit an AI reads. Most English words become one or two tokens, so a typical paragraph might be about 75–100 tokens.
Here’s where it gets interesting: different languages break into tokens very differently. And this difference determines how much your AI “understands” and how much it costs you.
When you feed text to an AI model, it converts every character into these tokens using an algorithm called tokenization. This algorithm was largely designed around English and similar languages. Languages with different writing systems or grammatical structures get chopped up much less efficiently — sometimes breaking a single word into 5 or even 10 tokens.
Imagine you’re trying to read a book, but someone randomly tears out pages from the middle of every chapter. That’s essentially what happens when certain languages get tokenized inefficiently. The AI has to work with fragments of meaning instead of complete thoughts. Your Chinese text that fits on one page might consume 2–3 times as many tokens as the equivalent English text — meaning the AI is processing fragments and struggling to maintain context.
This isn’t just a technical curiosity. It directly affects three things you care about:
Accuracy: More fragmentation means more chances for the AI to misunderstand
Cost: Many AI services charge per token, so inefficient tokenization means you pay more for the same content
Length limits: If your Chinese document uses 3x more tokens than English, you hit the AI’s length limit 3x faster
Recent research confirms these tokenization inequalities persist even in the newest models. A 2024 study analyzing GPT-4 and Claude found that languages like Tamil and Telugu require 3–5 times more tokens than English for the same content, while even major languages like Arabic and Hindi consume 2–3x more tokens. Another 2025 study showed that these disparities haven’t improved with newer tokenizers — in fact, some languages have gotten worse as models prioritized English-centric optimizations.
The Performance Puzzle: Why Polish Wins
Polish consistently topped the charts across nearly all models and document lengths. Why? The researchers don’t have a definitive answer, but they identified three factors that seem to matter:
Script compatibility: Polish uses the Latin alphabet, just like English. This means it tokenizes efficiently — words don’t fragment into tiny pieces like they do in some other languages.
Language structure: Polish has what linguists call “fusional morphology,” which essentially means it packs a lot of grammatical information into each word efficiently. This density of meaning in fewer tokens helps AI models track context better.
The Goldilocks zone: Polish has substantial online presence — about 1.6 million Wikipedia articles — but not overwhelming dominance. This seems to create a sweet spot where models have enough exposure to handle the language well, without the kind of biases that might come with dominant languages.
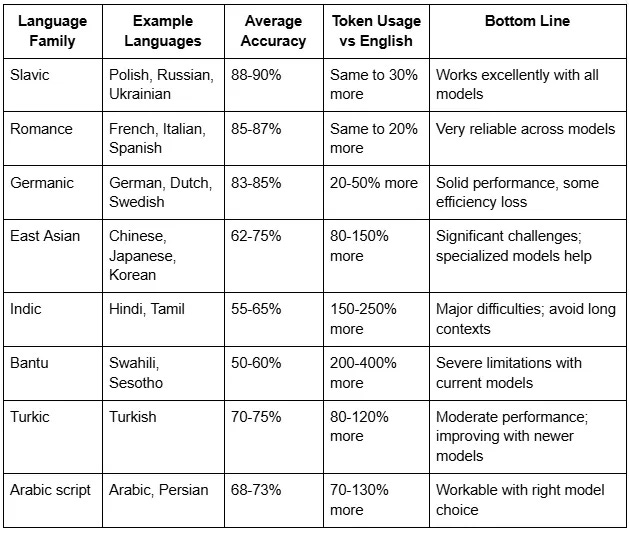
Slavic languages generally performed exceptionally well, some of them achieving 87–88% accuracy, similarly outperforming English, despite using Cyrillic script. Romance languages — French, Italian, and Spanish also beat English, scoring 85–87%.
The Chinese Conundrum
Chinese’s poor showing — 62.1% accuracy despite massive training data — highlights the tokenization problem most dramatically. Modern Chinese writing uses characters where each one represents a meaning. But byte-pair encoding (the tokenization algorithm most AI models use) was designed for alphabetic languages.
As a result, GPT-4 splits 89% of Chinese characters into multiple tokens, often breaking apart the semantic radicals — the component parts that give characters meaning. It’s like taking the word “unlikely” and forcing an AI to process it as “un-like-ly” without understanding how the parts connect.
This means when you upload a Chinese document, you’re actually giving the AI 2–3 times less actual content than the token count suggests. A model advertising “128,000 token capacity” effectively only processes 40,000–60,000 tokens worth of actual Chinese content.
Even specialized Chinese models like Qwen, trained on trillions of Chinese tokens, can’t fully overcome this structural limitation — though they do perform significantly better than general-purpose models.
What About Other Languages?
Languages with smaller digital footprints face compounded challenges. Hindi and Tamil speakers, despite representing hundreds of millions of people, saw their languages perform poorly — achieving only 55–65% accuracy even with the best models.
African languages faced the steepest penalties. Sesotho (12 million speakers) ranked last despite using the Latin alphabet. Swahili, with 87,000 Wikipedia articles, couldn’t overcome tokenization inefficiency. These languages tend to be “agglutinative” — they build long words by stringing together many small meaning units, which causes extreme token fragmentation.
Arabic, Turkish, and Persian fell somewhere in the middle — working reasonably well with models that have expanded vocabularies to better handle their scripts, but still consuming 1.7–2.0 times more tokens than English for the same content.
Practical Strategies: How to Get Better Results
Now that you understand the landscape, here are actionable strategies to improve your results when working with AI on long documents.
1. Be Explicit When You Know an Answer Exists
The Finding: Adding “or say ‘none’ if it doesn’t exist” caused a 32% performance drop.
What this means: Models become overly cautious and incorrectly claim things don’t exist when you give them the “out” of saying “none.”
Do:
✅ GOOD: “This contract contains a delivery date. Find it and tell me exactly what it says.”✅ GOOD: “The CEO mentioned revenue in this transcript. Quote the specific sentence.”
Don’t:
❌ BAD: “What’s the delivery date in this contract? If there isn’t one, say ‘none’.”❌ BAD: “Find mentions of revenue, or tell me if there aren’t any.”
Exception: Only add “or say if it’s not there” when you genuinely don’t know whether the information exists and need the AI to tell you.
2. Ask for Retrieval, Not Aggregation
The Finding: Retrieval accuracy = 80–90%. Aggregation accuracy = 0–30%.
Models ARE GOOD at finding things:
✅ “Find all mentions of ‘budget constraints’ in these meeting notes” ✅ “What did John say about the Q3 timeline?” ✅ “Extract every date mentioned in this contract” ✅ “Quote all sentences discussing data security”
Models ARE BAD at counting and pattern-finding:
❌ “What are the 10 most common complaints in these reviews?” ❌ “Count how many times each competitor is mentioned” ❌ “Rank the issues by how frequently they appear” ❌ “Which themes appear in all three novels?”
Workaround for aggregation tasks:
Step 1: “List every mention of competitors in this document” [AI retrieves all instances]Step 2: Copy the results into Excel/Google SheetsStep 3: Use spreadsheet tools to count and rankAlternative approach: - Break document into smaller chunks - Ask AI to find themes in each chunk separately - Manually synthesize the patterns yourself
3. Use Shorter Contexts Whenever Possible
The Finding: Performance drops dramatically from short to long documents. The gap widens for low-resource languages (11% drop → 34% drop).
Don’t:
❌ “Here are 50 customer support tickets [100K tokens]. Find patterns and suggest improvements.”
Do:
✅ Pass 1: “Summarize each of these 10 tickets in 2 sentences” [Repeat for all 50 tickets in batches]✅ Pass 2: “Based on these summaries, identify the 5 most common issues”
✅ Pass 3: “For each common issue, suggest one improvement”
General strategy:
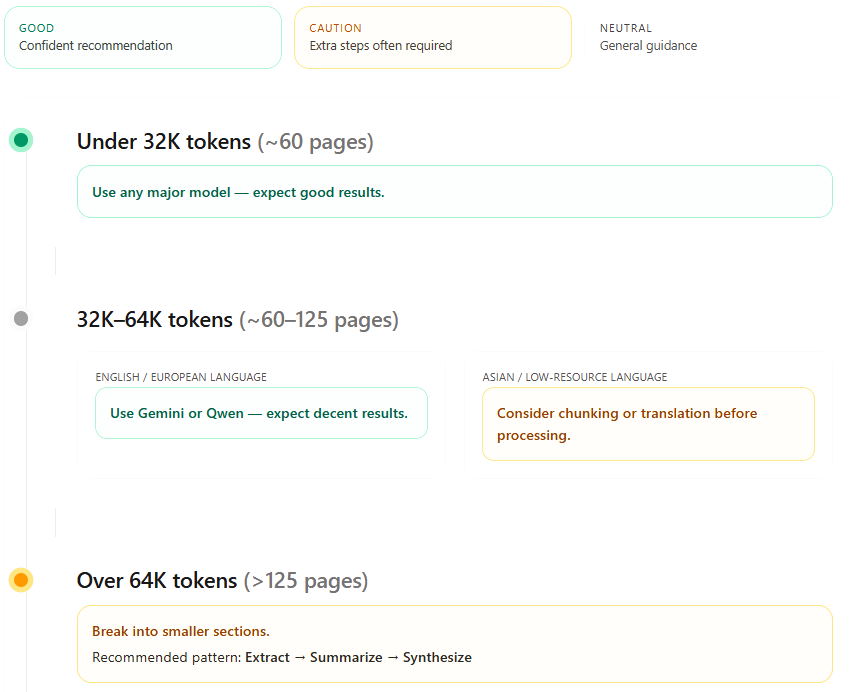
Keep individual prompts under 32K tokens (roughly 60 pages) when possible
Use the pattern: Extract → Summarize → Synthesize
Don’t assume models can handle their advertised maximum context length effectively
Real-world context limits:
8K-32K tokens: Excellent performance for most languages
32K-64K tokens: Good for high-resource languages (English, French, Polish)
64K-128K tokens: Noticeable accuracy drop, especially for low-resource languages
Above 128K tokens: Consider this risky for production work
4. Choose Your Model Based on Your Language
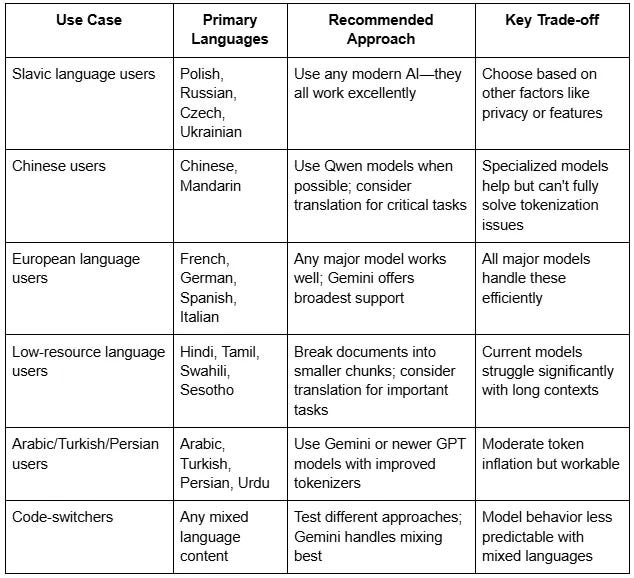
The Finding: Gemini 1.5 Flash and Qwen 2.5 perform best overall, but different models excel at different languages.
For long English documents:
✅ Gemini 1.5 Flash (best overall consistency) ✅ Qwen 2.5 (strong alternative) ⚠️ Avoid o3-mini (surprisingly weak at 67% accuracy despite being a “reasoning” model)
For European languages (French, Spanish, German, Polish, Italian):
✅ Any major model performs well ✅ All achieve 85-90% accuracy → Choose based on other factors (privacy, cost, features)
For Chinese, Japanese, Korean:
⚠️ Performance significantly weaker (62-75% accuracy) ✅ Use Qwen models if possible (specialized tokenizer helps) ✅ Consider shorter contexts (under 32K tokens) ✅ For critical tasks, translate to English first
For low-resource languages (Hindi, Tamil, Swahili, Sesotho):
⚠️ All models struggle (50-65% accuracy) ❌ Avoid long contexts entirely ✅ Keep contexts under 16K tokens (about 30 pages) ✅ Consider translation strategy for important work ✅ Use Gemini 1.5 Flash (least bad option)
5. Match Instruction Language to Content — Usually
The Finding: Performance can swing by 20% based on whether instructions and content are in the same language.
General rule:
✅ BEST: Instructions in the same language as contentExample: Korean instructions + Korean document “[Korean text]: 이 문서를 요약해 주세요”
Exception for low-resource languages:
Sometimes better: English instructions + Hindi/Tamil/Swahili contentExample: ✅ “Summarize this document: [Hindi text]” May work better than Hindi instructionsWhy: Models have more training on following English instructions
Test both approaches for your specific language combination. The “right” answer varies by language pair and model.
6. Don’t Trust “None” Answers at Long Contexts
The Finding: Models incorrectly answer “none” frequently even when information clearly exists. o3-mini is especially prone to this.
If you get “I don’t see that information”:
✅ Step 1: Try reformulating with certainty “This document definitely contains the pricing terms. Find them and quote the exact text.”✅ Step 2: Try being more specific Instead of: “Find the price” Try: “Find the number preceded by ‘$’ or the word ‘price’”✅ Step 3: Search in smaller sections “In pages 1-30, find any mention of pricing” Then: “In pages 31-60, find any mention of pricing”✅ Step 4: Verify manually Don’t trust negative results for important information
Red flag: If a reasoning model says “none” for a long document, be especially skeptical. Reasoning models are paradoxically worse at simple retrieval.
7. For Critical Work: Use Multiple Passes
The Finding: Even the best models achieve only 70–80% recall on long documents.
For high-stakes information:
✅ Pass 1: “Find all mentions of [liability/risk/deadline] in this contract”✅ Pass 2: “I found these mentions: [paste results]. Search again carefully—did I miss any?”✅ Pass 3: “In sections 5-8 specifically, find any mentions of [liability/risk/deadline]”Then: Compare all three sets of results
✅ Extract specific facts “What’s the project deadline mentioned?”✅ Find quotes “What did the CFO say about expenses?”✅ Answer questions with clear, specific answers “Which vendor was selected?”✅ Summarize overall themes (with decreasing reliability as documents get longer)✅ Compare 2-3 specific items “Does Contract A or Contract B have better payment terms?”
Models CANNOT reliably do:
❌ Count accurately “How many times is ‘compliance’ mentioned?” → Use Ctrl+F/Cmd+F instead❌ Rank by frequency “What are the top 10 customer concerns?” → Extract all concerns, then count manually❌ Identify all instances Expect only 70-80% recall at best❌ Complex reasoning across 100+ pages Break into smaller sections❌ Maintain high accuracy above 64K tokens Performance degrades significantly
Model Choice By Token Length: Quick Decision Guide
Performance by Language: What to Expect
Expected accuracy by language family (long documents)
The Bigger Picture
The OneRuler benchmark reveals something fundamental about how AI language models work — and don’t work. Despite enormous advances in AI capabilities, the way these systems process language remains surprisingly dependent on factors that have little to do with how many speakers a language has or how important it is globally.
This matters beyond just technical performance. As AI becomes more embedded in education, work, healthcare, and daily life, these language gaps can reinforce existing inequalities. A Polish business analyst and a Tamil business analyst might have the same analytical skills, but the AI tools they rely on will serve them very differently.
For now, the key takeaways are clear:
The 3 Most Important Rules:
Shorter is better — Don’t use long contexts unless necessary. Break documents into sections when possible.
Retrieval works, aggregation doesn’t — Ask AI to “find X” not “count all X” or “identify patterns across.”
Verify critical information — Models fail 20–50% of the time on long documents. Use multiple passes for high-stakes work.
The technology is impressive but imperfect. Use it to accelerate your work, not replace your judgment. Test your specific use case. Be aware of your language’s limitations. And always verify important information rather than trusting AI outputs blindly.
As models continue to improve, we can hope these disparities shrink. But for now, understanding these limitations helps you use AI more effectively — whatever language you’re working in.
Stanislav Lvovsky
Poet, historian, researcher. Is the author of books, numerous articles in humanities publications, and scholarly works. At the Prague Media School, is responsible for negotiations with large language models (LLMs), the training of AI assistants, and the philosophy of consciousness.